
最近几年,“人工智能”和“机器学习”成为金融投资圈中的一个热门词。
举例来说,2017年年底,创新工场创始人李开复在其主题演讲《人工智能四波浪潮与机会》中说道:
有了人工智能以后,它可以去计算哪些中国股票搭配起来跟哪些欧洲、美国股票应该是可以对冲的,它可以判断任何市场有任何不平衡的地方,它可以利用现在人民币换美金的交易障碍,来做更好的对冲,或者它可以判断怎么样能够最优化你该买什么样的股票。
过去两年其实我已经没有做任何的个人投资了,我也不把钱交给人了,我现在所有新生产出来的钱都交给机器处理,人已经不能再管理我的钱了,因为人打不过机器,这是非常明确的事情,我们个人投资的这些基金不太好意思分享回报率,回报是不低的,然后是零风险的,它每一天晚上结帐,我可以看到钱全部都卖掉回来了。
李开复的意思,是他投到了一个以人工智能算法为核心的基金,零风险,日结账,高回报。作为一名投资行业的“老兵”,说实话,我还没见过这样的基金。即使是对冲基金行业那些全球最顶尖的大牌:Bridgewater, Citadel, AQR, Quantum, Renaissance等, 也没听任何人敢自称零风险,而且每天都能赚。
但是我相信,很多读者一定还有这个疑问:人工智能,到底能不能用在投资领域?在金融市场上有哪些应用?我们应该如何认识人工智能和机器学习的价值?今天这篇文章,就来讲讲这些问题。
首先,让我们来简单介绍一下什么叫机器学习。
在本人和量化交易员和金融作家,Rob Carver的对话中,我们曾经谈到过这个问题。
大致来讲,机器学习可以被分为两种:有人管的机器学习(Supervised Machine Learning)和没人管的机器学习(Unsupervised Machine Learning)。

有人管的机器学习,是指工程师定义研究的变量。这种“机器学习”,其实和传统意义上的量化交易策略研究没有多大区别。很多这样的机器学习,用的还是最小二乘法(OLS)和主成分分析(PCA)这样的统计方法,而这些统计方法至少已经被用了几十年。一些机构放上“机器学习”和“人工智能”的标签,主要就是为了追求一个噱头,在营销上让人产生“高大上”的错觉。
这些“挂羊头卖狗肉”的人工智能,值得我们投资者警惕。本来可以用一些比较简单的传统量化手段实现的交易策略,披上了“人工智能”的外衣,反而增加了投资成本和没有必要的复杂之处,效果也不见得更好,对投资者来说没有什么价值。
真正有技术含量的,开复博士上面提到的人工智能,是没人管的机器学习。在这种机器学习中,电脑程序自己选择最优的变量进行分析和计算。这是真正尖端的人工智能领域,对数据处理和计算能力要求非常高,目前仅在高频交易领域有一些尝试性的应用。
为什么仅在高频交易领域有初步的应用呢?这是因为,人工智能在任何领域应用的一大前提,就是有海量数据。
在同一个演讲中,李开复谈到:
AI其实特别关键的就是大量的数据,有了数据...就都可以做了,没有数据是不可能的。
为什么需要海量数据?
这是因为,人工智能和机器学习的本质,就是数据挖掘。数据挖掘的意思,就是基于海量的数据,去找出一些不为大家所知的规律,并且期望该规律在未来继续管用。大家可以想一下,如果没有海量的数据,你还去挖掘什么?没东西可挖呀。
用科学的语言来讲,如果数据量不够,那么总结出来的任何规律,都是基于小样本的特殊情况,未来继续重复管用的可能性不大。
和其他行业相比,金融市场的数据量,恰恰少的可怜。以全世界数据量最丰富的美国市场为例。比较高质量的美国股市价格历史数据,也就50~60年左右,再往前推,数据质量就开始有问题了。一般的金融研究,以月回报为单位。5、60年历史,一共就700个数据样本。基于700个样本去做人工智能?Are you kidding me?
我们再看上市公司的财报数据。美国有差不多4000个上市公司。假设每个公司都有高质量的季报,往回走50年,数据量大约是 4000 X 50 X 4 = 80万。这样的样本量,显然离人工智能的要求差远了。
美国尚且如此,中国的股市数据就更不用提了,相信读者朋友们都有自己的认识。
当然,有些人说,我可以拿每天/每小时/每分钟的数据,这样数据量就大了。或者我在横向增加测试的变量,这样也能增加样本量。话虽不错,但问题在于数据的频度越高,噪音也越大。变量之间的交叉度越高,相关系数也越高,因此得出的结论,也有更大存疑。
在量化金融研究中,码农最容易犯的错误,就是忽略经济逻辑去做数据挖掘。在一大堆没有意义的数据中,你不断折腾,总能找出个貌似有用的投资策略来。但如果背后没有符合逻辑的经济原因去支撑,那这种发现就毫无意义。
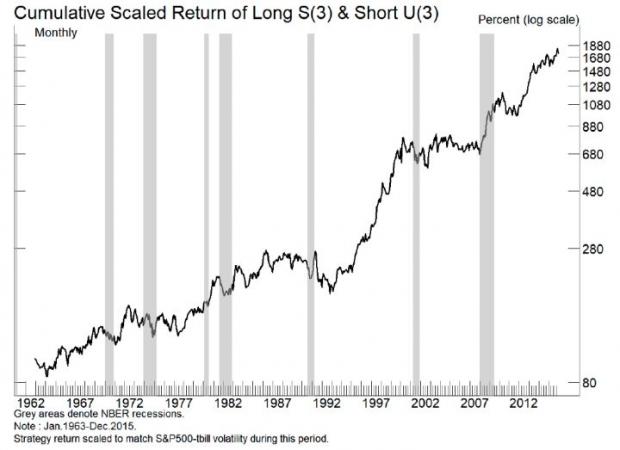
举例来说,上图来自于Robert Arnott, Campbell Harvey和Harry Markowitz合写的A Backtesting Protocol in the Era of Machine Learning (Arnott, et al, 2018)。它显示的是一个股票多空投资策略的历史回报。
我们可以看到,该投资策略,看上去非常诱人。因为:
第一、无论在1963~1988年的样本内测试,还是1989~2015年的样本外测试,该策略的表现都非常出色。
第二、即使在最近几年(比如2013年以后),该策略的投资回报还是非常出色,显示并没有很多人模仿,因此这个“秘密”还相当管用。
第三、该策略在2008年金融危机期间,得到的投资回报为+50%左右,秒杀市场上绝大多数的各种投资策略。
第四、该策略和其他主要资产(比如股票、债券等)之间的相关系数很低,从资产配置的角度,能够提高投资组合的风险调整后收益。
很多人看到这样的投资策略,可能已经迫不及待想要进行投资了。但事实上,该投资策略很简单,就是买入美国股票代码前三个字母中含有S的股票,并且做空股票代码前三个字母中含有U的股票。
为什么会想出这么一个奇怪的投资方法,去买入首三个字母中带有S的股票,并且做空首三个字母中带有U的股票?原因在于,这是基于大数据机器学习的方法,在成千上万种不同的投资策略中,甄选出来的表现最好的策略之一。我们可以想象一下,英语里有26个字母,从股票代码的第一个字母开始,然后前两个,前三个,这样不停的两两组合,买卖对配试下去。只要可能的组合够多,即使完全源于运气,也可能找出几个看上去非常牛逼的投资策略。
这个例子,点出了基于数据挖掘的人工智能用于投资管理的命门。那就是:如果反复“折磨”你的数据,对它“严刑拷打”,总有一天它会屈服,给出你想要的结果。但是,这个结果,对投资者来说未必有任何价值。
有美国学者(Chordia et al, 2017)在检验了210万个不同的股票投资策略后,发现其中只有17个策略通过了统计和经济标准,显示其可能有效。在这个例子中,发现真正有效的投资策略的概率,为17/210万=0.0008%!换句话说,在210万个投资策略中,超过209万个都是无效的。
这些例子告诉我们:
1)要想把人工智能运用到金融市场,一个最基本的前提,是我们有海量的高质量数据。如果一个市场中本来高质量数据就很有限,那人工智能写的算法再高级,也是“巧妇难为无米之炊”。
2)如果通过一些方法获得海量数据,并基于一些数据挖掘的方法去寻找规律,那么我们就需要十分提防“随机假规律”的陷阱。
随机假规律的意思,是只要我们做足够多的尝试,总能发现一些貌似管用的规律,在统计上显示出显著的结果(T值大于2)。但事实上,这只是一种假象而已。
在AHM(Arnott et al, 2018)一文中,作者提到这么一个有趣的例子。有学者(Bem, 2011)在顶级期刊上发表了一项研究结果。该研究结果来自于一个长达10年,覆盖1000个样本量的详细实验。从统计上来说,该实验结果不可靠的概率,为740亿分之一。但最后显示,该实验结果无法复制,因此从其中发现的规律,也不管用。
在所有的金融量化研究中,一个非常重要的原则,是“理论先行”。就是说,我们首先得有一套适用的,符合逻辑的经济理论,去预测基于某些条件,会导致某种结果。然后,再用数据去进行实证检验。而很多扯着“人工智能”大旗的交易策略,恰恰反着来:不管三七二十一,先从数据回测中找出表现好的,然后再动脑筋去解释其表现。这样的研究方法,本末倒置,对职业素养不高的投资者有很强的迷惑性,值得广大投资者警惕。
“理论先行”,有金融行业的特殊性,和其他一些行业很不相同。举例来说,在医学界,你可以先试药,试下来发现管用后,再去研究为什么管用,是里面某种成分管用,还是对人的某个基因管用。先实践,后理论,在医学界是可行的。
但这种做法,在金融投资里,不管用。这其中有一个非常重要的原因,那就是,金融市场是由人组成的,其本质是人的心理和行为。金融市场上的那些数字,只是一个表象,反映的无非就是股权/房地产/债务类资产的期望回报。所以说到底,金融市场反映的是人的期望。
因此对于金融市场的预测,本质上是对众人行为和心理的预测。而人的行为模式,恰恰在于不可预测。这是因为,人不是机器,有情绪波动,容易健忘,好吃懒做,贪生怕死,上涨时贪婪,下跌时害怕。说到底,人远不如机器自律。用机器思维去预测人,就好像让你猜3岁的孩子啥时候哭一样,成功率能有多高?
当然,值得指出的是,电脑程序在投资方面的用途还是很广泛的。现在最老派的基本面基金经理,也会大量用到量化模型和数据。但这和完全摆脱人,让机器做所有的投资决策,甚至宣扬能够做到零风险和高回报是两回事,值得我们大家思考。
希望对大家有所帮助。

参考资料:
https://
Robert Arnott, Campbell Harvey, and Harry Markowitz, A Backtesting Protocol in the Era of Machine Learning, Nov 2018
Robert Carver (Trader and Writer):How to become a systematic trader?
Chordia, Tarun, Amit Goyal, and Alessio Saretto, p-Hacking: Evidence from Two Million Trading Strategies. Swiss Finance Institute Research Paper No. 17-37.
Bem, Daryl.“Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect.” Journal of Personality and Social Psychology, vol. 100, no. 3 (March 2011): 407–425.

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}